
JS 常见面试题1
1.forin 与 forof 的区别
当使用forin和forof循环时,有一些重要的区别需要注意:
for...in 循环:
遍历对象的属性:
for...in主要用于遍历对象的可枚举属性,而不是值。它会返回属性名(键)。包括原型链上的属性: 这种循环会包括对象原型链上的属性,因此需要额外的检查来排除不必要的属性。
通常使用
hasOwnProperty方法来检查属性是否是对象自身的属性。适用于普通对象:
for...in对于普通对象是非常有用的。
示例:
const person = {
name: "John",
age: 30,
};
for (const key in person) {
if (person.hasOwnProperty(key)) {
console.log(key, person[key]);
}
}
for...of 循环:
遍历可迭代对象的值:
for...of主要用于遍历可迭代对象的值,例如数组、字符串、Set、Map 等。它会返回对象中的值本身,而不是属性名。不包括原型链上的属性: 这种循环不会访问对象原型链上的属性,因此不需要额外的检查。
适用于数组和可迭代对象:
for...of对于数组和其他可迭代对象是非常有用的,因为它让你可以轻松地遍历它们的值。
示例:
const numbers = [1, 2, 3, 4, 5];
for (const value of numbers) {
console.log(value);
}
总之,for...in 用于遍历对象的属性,而 for...of 用于遍历可迭代对象的值。选择使用哪种循环取决于你要处理的数据类型。如果处理对象属性,使用 for...in;如果处理数组或其他可迭代对象的值,使用 for...of。这两种循环有不同的用途和适用场景。
2.如何判断一个变量是否为数组
2.1 Array.isArray()
在 JavaScript 和 TypeScript 中,您可以使用 Array.isArray() 方法来判断一个变量是否为数组。这个方法会返回 true 如果变量是一个数组,否则返回 false。
下面是一个示例:
const myArray = [1, 2, 3];
if (Array.isArray(myArray)) {
console.log("myArray 是一个数组");
} else {
console.log("myArray 不是一个数组");
}
在上面的代码中,我们首先创建一个数组 myArray,然后使用 Array.isArray() 方法来检查它是否为数组。由于 myArray 是一个数组,所以条件成立,会输出 "myArray 是一个数组"。
2.2 instanceof操作符
您可以使用 JavaScript 中的 instanceof 操作符来检查一个对象是否是特定类的实例,而数组是 JavaScript 中的一种特殊对象。例如:
const myArray = [1, 2, 3];
if (myArray instanceof Array) {
console.log("myArray 是一个数组");
} else {
console.log("myArray 不是一个数组");
}
这也可以用来判断变量是否为数组。
2.3 检查构造函数:
您可以检查对象的构造函数是否为 Array 构造函数。例如:
const myArray = [1, 2, 3];
if (myArray.constructor === Array) {
console.log("myArray 是一个数组");
} else {
console.log("myArray 不是一个数组");
}
这种方法也可以用来判断变量是否为数组。
虽然这些方法可以用来检查数组,但通常推荐使用 Array.isArray() 方法,因为它是最简单和最可靠的方式来检查一个值是否为数组。
3.事件与事件流
javascript 中的事件,可以理解就是在 HTML 文档或者浏览器中发生的一种交互操作,使得网页具备互动性,常见的有加载事件、鼠标事件、自定义事件等
由于 DOM 是一个树结构,如果在父子节点绑定事件时候,当触发子节点的时候,就存在一个顺序问题,这就涉及到了事件流的概念
事件流都会经历三个阶段:
1.事件捕获阶段(capture phase)
2.处于目标阶段(target phase)
3.事件冒泡阶段(bubbling phase)
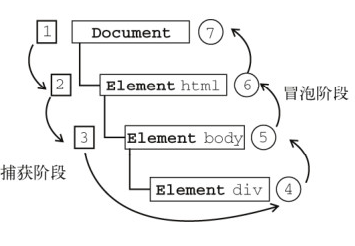
事件冒泡是一种从下往上的传播方式,由最具体的元素(触发节点)然后逐渐向上传播到最不具体的那个节点,也就是 DOM 中最高层的父节点
标准事件模型
在该事件模型中,一次事件共有三个过程:
事件捕获阶段:事件从 document 一直向下传播到目标元素, 依次检查经过的节点是否绑定了事件监听函数,如果有则执行(useCapture 设置为 true 执行)
事件处理阶段:事件到达目标元素, 触发目标元素的监听函数
事件冒泡阶段:事件从目标元素冒泡到 document, 依次检查经过的节点是否绑定了事件监听函数,如果有则执行(useCapture 设置为 false 执行)
事件绑定监听函数的方式如下:
addEventListener(eventType, handler, useCapture);
事件移除监听函数的方式如下:
removeEventListener(eventType, handler, useCapture);
参数如下:
eventType: 指定事件类型(不要加 on)handler:事件处理函数useCapture: 默认为 false,是一个 boolean 用于指定是否在捕获阶段进行处理,一般设置为 false 与 IE 浏览器保持一致
4.javascript 中的 instanceof 原理
4.1 instanceof 原理
instanceof 是 JavaScript 中用于检查一个对象是否是某个构造函数的实例的运算符。
它的原理是检查对象的原型链上是否存在指定构造函数的原型对象。
具体来说,instanceof 操作符会从对象的 __proto__ 属性开始,一直向上遍历原型链,
直到找到指定构造函数的原型对象,如果找到了就返回 true,否则返回 false。
例如,假设有如下的构造函数和对象:
function Animal() {}
function Dog() {}
Dog.prototype = new Animal();
const myDog = new Dog();
你可以使用 instanceof 来检查 myDog 是否是 Animal 和 Dog 的实例:
console.log(myDog instanceof Animal); // true
console.log(myDog instanceof Dog); // true
这是因为 myDog 的原型链中包含了 Animal 和 Dog 构造函数的原型对象。
需要注意的是,instanceof 只能用来检查对象是否是某个构造函数的实例,不能用来判断对象是否是基本数据类型(如字符串、数字等)的实例。此外,如果对象的原型链被修改,instanceof 可能会产生意外的结果,因此在使用时要小心。
4.2 instanceof 代码实现
function customInstanceOf(obj, constructorFn) {
// 获取对象的原型
let prototype = Object.getPrototypeOf(obj);
// 从对象的原型开始,一直遍历原型链
while (prototype !== null) {
// 如果找到了目标构造函数的原型,返回 true
if (prototype === constructorFn.prototype) {
return true;
}
// 否则继续向上遍历原型链
prototype = Object.getPrototypeOf(prototype);
}
// 如果遍历完整个原型链都没有找到目标构造函数的原型,返回 false
return false;
}
// 测试示例
function Animal() {}
function Dog() {}
Dog.prototype = new Animal();
const myDog = new Dog();
console.log(customInstanceOf(myDog, Animal)); // true
console.log(customInstanceOf(myDog, Dog)); // true
console.log(customInstanceOf(myDog, Object)); // true(因为所有对象都继承自 Object)
console.log(customInstanceOf(myDog, Array)); // false
5. JS 高阶函数
5.1 接受一个或多个函数作为参数,或者作为返回
JavaScript 中的高阶函数是一种特殊类型的函数,它们可以接受一个或多个函数作为参数,或者将函数作为返回值返回。
高阶函数常常用于函数式编程和处理集合数据(如数组)的操作。以下是一些常见的高阶函数:
map:map是一个用于数组的高阶函数,它接受一个函数作为参数,并对数组中的每个元素应用该函数,然后返回一个新数组,其中包含了应用函数后的结果。
const numbers = [1, 2, 3, 4];
const doubled = numbers.map((num) => num * 2);
console.log(doubled); // [2, 4, 6, 8]
filter:filter也是数组的高阶函数,它接受一个函数作为参数,用于筛选数组中的元素,返回一个包含满足条件的元素的新数组。
const numbers = [1, 2, 3, 4, 5];
const evenNumbers = numbers.filter((num) => num % 2 === 0);
console.log(evenNumbers); // [2, 4]
reduce:reduce用于对数组中的元素进行累积操作,接受一个函数作为参数,该函数定义了如何将元素累积到一个最终的值中。
const numbers = [1, 2, 3, 4];
const sum = numbers.reduce(
(accumulator, currentValue) => accumulator + currentValue,
0
);
console.log(sum); // 10
forEach:forEach是一个简单的高阶函数,用于迭代数组中的每个元素,并对其执行指定的操作,通常没有返回值。
const fruits = ["apple", "banana", "cherry"];
fruits.forEach((fruit) => console.log(fruit));
// 输出:
// "apple"
// "banana"
// "cherry"
sort:sort是用于对数组排序的高阶函数,它可以接受一个比较函数,用于自定义排序规则。
const fruits = ["banana", "cherry", "apple"];
fruits.sort((a, b) => a.localeCompare(b));
console.log(fruits); // ["apple", "banana", "cherry"]
这些是一些常见的高阶函数,它们可以帮助你更方便地处理和操作数组数据,以及实现函数式编程的思想。
高阶函数的使用可以使你的代码更加模块化和易于理解。
5.2 函数的柯里化
函数柯里化(Currying)通常被认为是一种高阶函数的应用。
函数柯里化是一种将接受多个参数的函数转化为一系列接受单个参数的函数的过程。
这些单参数函数可以依次调用,每次调用返回一个新的函数,最终产生最终结果。
柯里化的特点是它接受一个函数,然后返回一个新的函数,这个新的函数可能也接受函数作为参数,从而形成一个函数链。
这个链式的函数调用方式是高阶函数的典型应用,因为它涉及到函数作为参数和返回值。
以下是一个简单的 JavaScript 示例来说明柯里化:
function add(a) {
return function (b) {
return a + b;
};
}
const add5 = add(5); // 返回一个新函数,可以用于加5
console.log(add5(3)); // 输出 8,5 + 3
在这个示例中,add 函数接受一个参数 a,然后返回一个新的函数,这个新函数接受参数 b,并返回它们的和。这种方式允许我们部分应用函数,将其拆分成多个步骤的函数调用,这是柯里化的核心思想。
因此,函数柯里化是高阶函数的一种典型应用,因为它涉及到函数作为参数和返回值,同时也提供了更灵活和模块化的函数调用方式。
5.3 redux 中 connect 作为柯里化使用
connect 是 React-Redux 库中的一个函数,用于连接 React 组件与 Redux 的状态管理。
它是 React-Redux 的核心功能之一,用于将 Redux 的状态(state)和操作(actions)与 React 组件关联起来。
使用 connect 可以将 Redux 的状态和操作作为 props 传递给 React 组件,从而使组件能够访问 Redux 存储中的数据并触发相应的操作。
基本语法如下:
import { connect } from "react-redux";
// 定义一个 React 组件
class MyComponent extends React.Component {
// ...
}
// 使用 connect 函数将组件连接到 Redux
const mapStateToProps = (state) => {
return {
// 在这里定义组件需要从 Redux 状态中获取的数据
// 例如:someData: state.someData
};
};
const mapDispatchToProps = (dispatch) => {
return {
// 在这里定义组件需要触发的 Redux 操作
// 例如:doSomething: () => dispatch({ type: 'SOME_ACTION' })
};
};
export default connect(mapStateToProps, mapDispatchToProps)(MyComponent);
上述代码中,connect 函数接受两个参数 mapStateToProps 和 mapDispatchToProps。它们分别定义了组件需要从 Redux 状态中获取的数据和需要触发的 Redux 操作。
mapStateToProps函数将 Redux 的状态映射到组件的 props 上,使组件能够访问 Redux 存储中的数据。mapDispatchToProps函数将 Redux 的操作映射到组件的 props 上,使组件能够触发 Redux 操作。
然后,通过将组件传递给 connect 函数,返回一个新的连接了 Redux 的组件。这个新的组件可以访问通过 mapStateToProps 和 mapDispatchToProps 定义的数据和操作。
使用 connect 可以轻松地将 React 组件与 Redux 集成,实现了组件的状态管理和数据流控制。
这是 React-Redux 库中非常常见且重要的用法之一。
6.闭包函数
6.1 闭包函数
闭包函数是:能够访问另一个函数作用域的变量的函数。当内部函数可以访问它们所在的外部函数中声明的所有局部变量、参数和声明的其他内部函数。当其中一个这样的内部函数在包含它们的外部函数之外被调用时,就会形成闭包。闭包函数使得函数内变量暴露给函数外访问。 基本介绍
关于闭包,最简单的描述就是 ECMAScript 允许使用内部函数--即函数定义和函数表达式位于另一个函数的函数体内。而且,这些内部函数可以访问它们所在的外部函数中声明的所有局部变量、参数和声明的其他内部函数。当其中一个这样的内部函数在包含它们的外部函数之外被调用时,就会形成闭包。也就是说,内部函数会在外部函数返回后被执行。而当这个内部函数执行时,它仍然必需访问其外部函数的局部变量、参数以及其他内部函数。这些局部变量、参数和函数声明(最初时)的值是外部函数返回时的值,但也会受到内部函数的影响。
闭包是 ECMAScript (JavaScript)最强大的特性之一,但用好闭包的前提是必须理解闭包。闭包的创建相对容易,人们甚至会在不经意间创建闭包,但这些无意创建的闭包却存在潜在的危害,尤其是在比较常见的浏览器环境下。如果想要扬长避短地使用闭包这一特性,则必须了解它们的工作机制。而闭包工作机制的实现很大程度上有赖于标识符(或者说对象属性)解析过程中作用域的角色。
标识符解析
标识符是沿作用域链逆向解析的。ECMA 262 将 this 归类为关键字而不是标识符,并非不合理。因为解析 this 值时始终要根据使用它的执行环境来判断,而与作用域链无关。
标识符解析从作用域链中的第一个对象开始。检查该对象中是否包含与标识符对应的属性名。因为作用域链是一条对象链,所以这个检查过程也会包含相应对象的原型链(如果有)。如果没有在作用域链的第一个对象中发现相应的值,解析过程会继续搜索下一个对象。这样依次类推直至找到作用域链中包含以标识符为属性名的对象为止,也有可能在作用域链的所有对象中都没有发现该标识符。
当基于对象使用属性访问器时,也会发生与上面相同的标识符解析过程。当属性访问器中有相应的属性可以替换某个对象时,这个属性就成为表示该对象的标识符,该对象在作用域链中的位置进而被确定。全局对象始终都位于作用域链的尾端。
自动垃圾收集
ECMAScript 要求使用自动垃圾收集机制。但规范中并没有详细说明相关的细节,而是留给了实现来决定。但据了解,相当一部分实现对它们的垃圾收集操作只赋予了很低的优先级。但是,大致的思想都是相同的,即如果对象不再"可引用(由于不存在对它的引用,使执行代码无法再访问到它)"时,该对象就成为垃圾收集的目标。因而,在将来的某个时刻会将这个对象销毁并将它所占用的一切资源释放,以便操作系统重新利用。
正常情况下,当退出一个执行环境时就会满足类似的条件。此时,作用域链结构中的活动(可变)对象以及在该执行环境中创建的任何对象--包括函数对象,都不再"可引用",因此将成为垃圾收集的目标。
6.2 闭包函数理解
当涉及到确定闭包函数与非闭包函数时,以下是更详细的解释和特征:
闭包函数:
内部函数引用外部变量: 闭包函数通常包括内部函数,这些内部函数引用了外部函数的一个或多个变量。这意味着内部函数可以访问和操作外部函数的变量。
外部函数返回内部函数: 通常,外部函数会返回内部函数,允许在外部函数的范围之外调用和使用内部函数。这是闭包的核心特征。
状态保持: 闭包函数可以维护状态,因为它们可以访问并修改外部函数的局部变量。这使得闭包函数在需要保持某些状态或数据的情况下非常有用。
示例:
function outerFunction() {
let outerVar = 10;
function innerFunction() {
console.log(outerVar); // 内部函数引用外部变量
}
return innerFunction; // 返回内部函数
}
const closureFunction = outerFunction(); // 获取闭包函数
closureFunction(); // 调用闭包函数,它仍然可以访问 outerVar
非闭包函数:
没有内部函数或外部变量引用: 非闭包函数不包含内部函数,或者即使包含内部函数,内部函数也没有引用外部函数的变量。它们是独立的函数。
直接调用: 非闭包函数通常直接被调用,而不需要返回内部函数供以后使用。
示例:
function regularFunction() {
console.log("This is a regular function.");
}
regularFunction(); // 直接调用,没有内部函数或外部变量引用
总之,闭包函数是一种具有内部函数和外部变量引用的函数,通常用于维护状态、封装和创建函数工厂。非闭包函数是独立的函数,没有内部函数或外部变量引用,它们通常直接被调用执行。理解这两者之间的区别对于编写和理解 JavaScript 函数非常重要。
6.2 闭包函数示例
封装和数据隐藏: 闭包函数可以用来封装数据,将数据隐藏在函数的作用域内,从而创建私有变量。这样可以防止外部直接访问和修改数据,提高了代码的安全性和可维护性。
function createCounter() { let count = 0; return function () { count++; console.log(count); }; } const counter = createCounter(); counter(); // 1 counter(); // 2函数工厂: 闭包函数可以用来创建函数工厂,动态生成具有不同配置或行为的函数。
function createMultiplier(factor) { return function (x) { return x * factor; }; } const double = createMultiplier(2); console.log(double(5)); // 10状态保持: 闭包函数可以用于在函数调用之间保持状态。这对于需要在多次调用之间共享信息的情况非常有用。
function createCounter() { let count = 0; return { increment: function () { count++; }, getCount: function () { return count; }, }; } const counter = createCounter(); counter.increment(); console.log(counter.getCount()); // 1回调函数: 闭包函数常用于处理异步操作,例如在事件处理程序或定时器回调中,因为它们可以访问函数外的变量。
function asyncOperation(callback) { setTimeout(function () { callback("Operation complete"); }, 1000); } asyncOperation(function (result) { console.log(result); });模块模式: 闭包函数可以用于创建模块,将相关的函数和数据封装在一起,实现模块化和隔离。
const myModule = (function () { let privateVar = 0; function privateFunction() { // 私有函数 } return { publicVar: 42, publicFunction: function () { // 可访问 privateVar 和 privateFunction }, }; })(); console.log(myModule.publicVar); myModule.publicFunction();
总之,闭包函数在需要创建私有作用域、封装数据、维护状态、实现函数工厂或处理异步操作等情况下非常有用。
它们提供了一种有效的方式来管理和组织代码,同时保持良好的封装和隔离。但请注意,滥用闭包也可能导致内存泄漏,因此需要谨慎使用。
7. 作用域
7.1 作用域的类型
在 JavaScript 中,存在几种不同类型的作用域,它们决定了变量在不同部分的代码中的可见性和生命周期。以下是一些主要的作用域类型:
全局作用域(Global Scope):
- 全局作用域是整个 JavaScript 程序的最外层作用域。
- 在全局作用域中声明的变量可以在程序的任何位置访问,它们的生命周期在整个程序运行期间。
- 全局作用域中通常定义的变量是全局变量,它们可以被任何函数访问。
const globalVar = 10; function myFunction() { console.log(globalVar); // 可以访问全局变量 }局部作用域(Local Scope):
- 局部作用域是由函数定义的作用域,变量在函数内部声明的话只能在该函数内部访问。
- 变量的生命周期仅限于函数的执行过程中,当函数执行完毕后,这些局部变量通常会被销毁。
function myFunction() { const localVar = 20; // 局部变量 console.log(localVar); // 可以访问局部变量 }块级作用域(Block Scope):
- 块级作用域是由
{}包围的代码块内部的作用域。 - 在块级作用域中声明的变量(使用
let或const)只在当前块级作用域内可见。 - 块级作用域通常出现在条件语句、循环和函数内部的代码块中。
if (true) { let blockVar = 30; // 块级变量 console.log(blockVar); // 可以访问块级变量 }- 块级作用域是由
函数作用域(Function Scope):
- 函数作用域是指在函数内部声明的变量在整个函数体内可见,但在函数外部不可见。
- 这是 JavaScript 的经典作用域,使用
var声明的变量具有函数作用域。
function myFunction() { var functionVar = 40; // 函数作用域 console.log(functionVar); // 可以访问函数作用域变量 }
了解这些不同的作用域类型对于编写结构良好的代码非常重要。
ES6 引入了 let 和 const 关键字,使块级作用域变得更加常见,而不仅限于函数作用域。
因此,现代 JavaScript 中更多地使用块级作用域以及函数作用域。
7.2 作用域的类型
在 JavaScript 中,作用域(scope)和作用域链(scope chain)是非常重要的概念,它们决定了变量的可见性和访问规则。
作用域(Scope):
- 作用域是指在代码中定义变量的区域,它规定了变量在哪些部分可以被访问和操作。
- JavaScript 有两种主要的作用域:全局作用域和局部作用域。
- 全局作用域包括整个 JavaScript 程序,全局作用域中的变量在任何地方都可访问。
- 局部作用域通常由函数定义,变量在函数内部定义的话,只能在该函数内部访问。
// 全局作用域 const globalVar = 10; function myFunction() { // 局部作用域 const localVar = 20; console.log(globalVar); // 可以访问全局变量 } myFunction();作用域链(Scope Chain):
- 作用域链是一个有序的列表,其中包含了在当前执行的代码块中可以访问的所有作用域。
- 当在某个作用域内查找变量时,JavaScript 引擎会首先查找当前作用域,然后逐级向外查找,直到找到变量或者抵达全局作用域为止。这个过程就形成了作用域链。
- 如果在任何作用域中找不到变量,JavaScript 将抛出一个 ReferenceError。
const globalVar = 10; function outerFunction() { const outerVar = 20; function innerFunction() { const innerVar = 30; console.log(globalVar); // 从内到外查找,可以访问 globalVar console.log(outerVar); // 可以访问 outerVar console.log(innerVar); // 可以访问 innerVar } innerFunction(); } outerFunction();
作用域和作用域链是 JavaScript 中实现变量可见性和封装的重要机制。了解它们可以帮助你编写更具结构和可维护性的代码。在函数嵌套的情况下,作用域链变得尤为重要,因为它决定了在内部函数中能否访问外部函数的变量。
